






謎だった「要約脳」の仕組みを追え

物語記憶の研究は古くから行われてきました。
英国のバートレット博士による古典的実験では、物語の記憶はその理解(解釈)と密接に結びついており、人によって想起内容に大きな差異が生じることが示されています。
その後の研究でも、物語の理解・想起には既有の知識構造(スキーマ)が影響を与えると考えられてきました。
つまり、意味のある物語の記憶は単純な暗記ではなく、読んだ人それぞれの知識と解釈によって再構成されるのです。
このように複雑な物語記憶を一般的な法則で説明することは難しく、少数の仮定で記憶現象を説明する単純モデルの構築は容易ではないとされてきました。
実際、ランダムな単語リストや数字列の記憶については、記憶できる項目数や忘却のパターンなど多くの定量的知見が蓄積しており、提示された項目数に対して平均何項目を想起できるかといった関係を予測するモデルも提案されています。
しかし物語のような意味を持つ情報では、人は物語を逐語的ではなく要点を要約して記憶するため、単純な語数では記憶の質を評価できません。
このような理由から、物語記憶に共通する定量的特徴を説明する理論はこれまで存在しなかったのです。
近年になって、この課題に挑むための大規模な実験データが集められ始めました。
ツォディクス氏らのチームは、様々な長さの物語を用いたオンライン実験を実施し、多人数の物語想起データを収集しました。
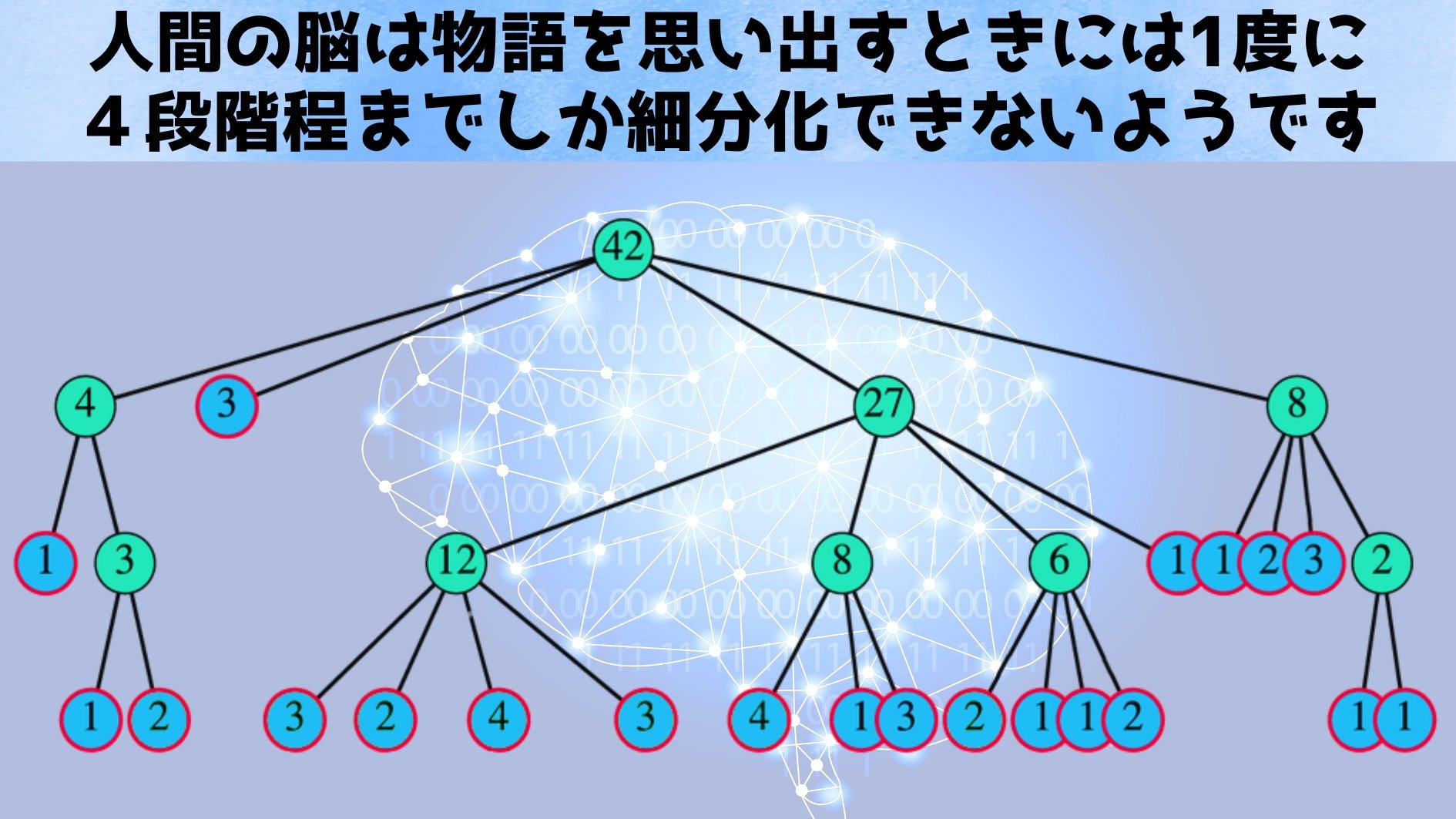
彼らの観察によると、人はランダムな単語リストとは異なり、物語を思い出すときには出来事を原作の順序通りになぞる傾向が強いことが分かりました。
さらに、物語が長くなるほど一つひとつの想起文に詰め込まれる内容が増え、全体の想起の長さ(文章数)の伸びは物語の長さそのものよりも緩やかになる(物語が長くなるにつれ相対的に要約が進む)ことも報告されています。
このような統計的規則性が見られるのは、記憶に階層的な要約メカニズムが働いている可能性を示唆していました。
研究チームはこれらの特徴を数理モデルで説明することを目指したのです。





















![シルバーバック 【釣って遊ぼう!サメまみれ!】 知育玩具 幼稚園 小学校 入園 入学 お祝い プレゼント 準備 ([バラエティ])](https://m.media-amazon.com/images/I/41ejNUfrJZL._SL500_.jpg)




























