FDSL(Formula-Driven Supervised Learning)とは?

今まで画像認識AIの開発には、大量の写真によるデータセットが不可欠でした。
しかし本研究では、数式から幾何画像によるデータセットの自動生成が可能になり、事前学習を行ったところ、従来のデータセットと同等以上の精度が実現できたということです。
この技術をFDSL(Formula-Driven Supervised Learning)といいます。
いったいなぜ、数式から画像データセットを作るというユニークな手法が必要だったのでしょうか。
少なくとも、人の手で数千枚、数万枚といった大量の写真を準備する大変さはイメージできると思います。
その労力が大幅に軽減されるだけでも大きな成果なのですが、それと同時に、従来の画像認識AI開発では生じやすい問題を回避できる技術としても期待されています。
従来の方法による問題点とは具体的にどのようなものがあり、FDSLにするとどのようなメリットがあるのでしょうか。
膨大な作業コストを超削減!
大規模なモデルを用いた画像認識AIには、あらかじめ大量の画像をインプットし、画像認識を学習させることで機能しているものがあります。
その開発過程では、人間がAIにやってほしい特定の画像認識をAIができるようにするため、初めに「事前学習」、次に「ファインチューニング」と二段階経ることがあります。
画像を見たことがない開発段階のAIは、まず大量の写真を読み込み「なるほど、画像の識別ってこうやるのか」と理解します。これが事前学習です。
それから、ファインチューニングといって、具体的にやってほしいタスクの例題をAIにたくさん解かせ、使用目的に合った判別が十分にできるよう調整がなされます。
本研究では、最初の工程の事前学習で「大量の写真」が不要となる新たな手法が開発されました。
これについて、まずは「事前学習」のプロセスから詳しくみていきましょう。
事前学習を例えるなら、人間の試験勉強のイメージです。
英語の試験なら「単語の暗記」や「文法問題を解く」といった勉強を経て、私たちは最終的に試験で高い点数を取ることができます。
それと同様で、画像認識AIも事前学習では、様々な写真を大量にインプットし、何が写っているのかを答えるという訓練を繰り返します。
なお、そのAIの答えが合っているかどうかは、予め人間がその写真に付けている「教師ラベル」によって判別されます。この学習の手法を「教師あり学習」といいます。
この教師あり学習を行うには、データセットに使用する写真を大量に収集するばかりでなく、収集したすべての写真に対し、人間が一枚ずつラベリングする作業を行わなければなりません。
100万枚以上ある写真の一枚一枚に対し「犬」「猫」など写っているもののカテゴリを人が判断し、付与する作業を想像してみてください。
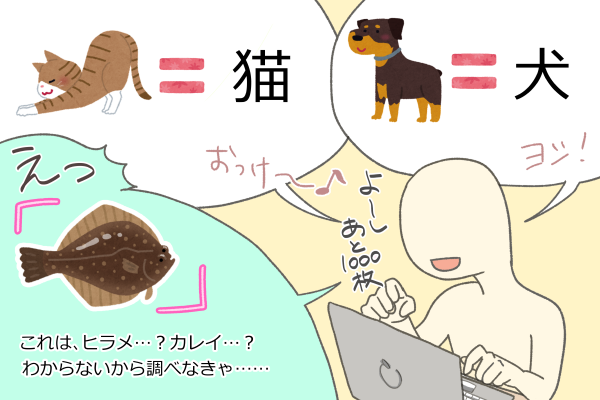
実際のラベリング作業は、もちろん少数で行うわけではありません。
例えば、現在よく使われる1400万枚以上の写真によるデータセット「ImageNet」の作成時には、クラウドソーシングから結果的に5万人ほどが作業に参加しましたが、それでも完成までに3年かかりました。
そして、仮に数万人がラベリング作業に参加できたとして、全員が正しい知識をもってカテゴライズできているとも限りません。
そのため、誤ったラベル付けを修正するためのダブルチェックや、段階に応じたデータの管理などが必要となり、時間がかかるうえに、人件費がかさみます。
そして、データセットは完璧な状態には至らず、数%は次のようなラベルの付け間違いが起こっているのも事実です。

このような明らかなミスがありえるのか?と言いたくなるのもわかります。
ですが実際、ウォーリーを探せのごとく、大量のデータに目を通して間違い探しを行うため、見逃しも起こり得るのでしょう。
大量の写真に対して人間が一枚ずつ手を加えるという条件では、正確性の面でも限界があるようです。
大規模な研究をしたいという気持ちがあっても、以上のような障壁があるとわかれば、研究者も簡単に手を出しづらいでしょう。
そこで、数式から画像データセットを自動生成できるFDSLの出番です。
本研究では、主に次のようなフラクタル幾何の画像が使われました。

片岡研究員は、植物などフラクタルの特徴をもつ本物の自然物から着想を得たそうです。
また、幾何学的構造のなかでも、フラクタル幾何は比較的単純な数式で作れるということでした。
そして、FDSLは画像の自動生成だけでなく、同時に教師ラベルを付ける作業も自動で行ってくれます。
教師ラベルは「124」「258」などの数字として、図形のカテゴリごと自動で割り当てられます。
こうして、人間の作業コストは大幅に削減され、ラベルの誤りについても心配無用となりました。
人工の幾何学的な画像が、現実世界の画像認識に役立つなんて不思議ですよね。
なぜ、実際の写真でなくてもよい可能性があるという考えに至ったのでしょうか。
産業技術総合研究所の公式Twitterで、片岡主任研究員は次のようにコメントしています(一部抜粋)。
初見でイヌとネコを識別するのは難しいので、まずはイヌネコに限らず「あらゆるモノを見分けるコツ」を教え込むわけです。
モノの見方を教えるだけなら、実物ではなくモノの特徴をもった図形でもよさそうな気がしますよね?こうして研究がスタートしました。
奇想天外な発想にも思えますが、これを実行に移したのはすごいですよね。
さて、この技術によって、作業コストのほかにも、データセットにありがちな諸問題が防げるといいます。
いったい他にどういった問題があったのか、次に見ていきましょう。





















![マモルーム お部屋まるごと予防空間 ダニ用 [2ヵ月用セット] ダニアレル物質の生成抑制・ダニを除去しやすくなる ダニよけ 加熱蒸散機 ダニ対策 (アース製薬)](https://m.media-amazon.com/images/I/413VgtLwPgL._SL500_.jpg)