


chatGPTの性能はバージョンアップにどう反応するのか?
GPT-3.5 や GPT-4 などの大規模言語モデル (LLM)は、設計の変更だけでなく、データやユーザーからのフィードバックに基づいて、時間の経過とともに更新できます。
最近では、より高性能なGPT-4 が医学や法律などの専門分野の難しい試験に合格することが示されました。
ただし、GPT-3.5 および GPT-4 がいつ、どのように更新されるかは現時点では非公開であり、安定して仕事に使うには困難がつきまといます。
特に質問(プロンプト)に対する 答えの(精度や形式など が突然変化すると、続く質問を入力しても、内容の整合性がとれなくなってしまいます。
また更新の前後では一般に同じ質問に対してGPTが異なる内容を回答するため、答えの一貫性や再現性を維持することが困難になります。
さらに、そもそもGPT4 のような LLM サービスが時間の経過とともに一貫して「改善」されているかどうかも興味深い問題です。
というのも現在、chatGPTなどの生成型AIは社会的に大きく注目されるようになっており、AIに要求される項目は極めて多岐に及んでいます。
(※かつては会話を目的に開発されたかため「会話型AI」と呼ばれていましたが、近年では会話以外も多様な能力が発見されていることからから生成型AIと呼ばれるようになっています)
そのためAIの開発元がそれらの問題を回避するような「変更」を行った場合、AIの性能に不都合な結果を及ぼしかねません。
研究者たちも「いくつかの問題を改善するためのモデル変更が、他の機能に悪影響を与える可能性がある」と述べています。
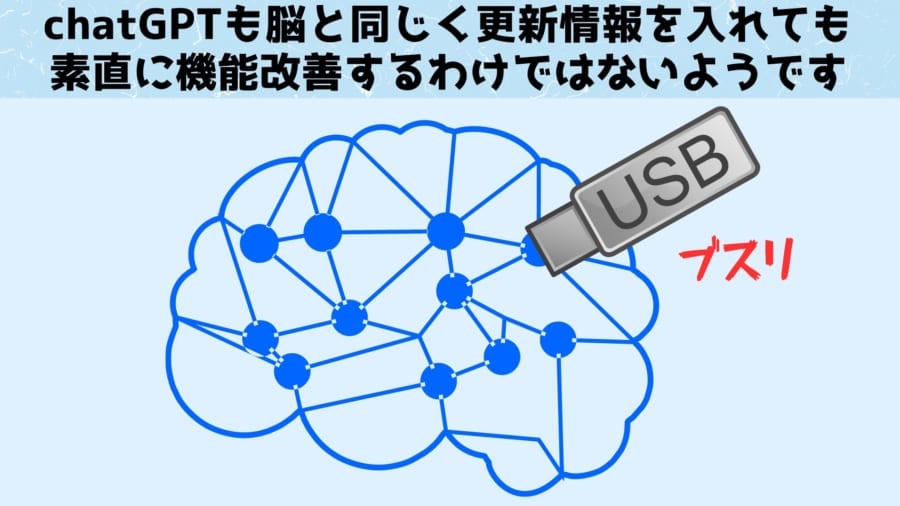
chatGPTは人間の脳を模した疑似的な神経ネットワークによって構成されているため、通常のプログラムのように「パッチ」を当てても素直に機能が改善するとは限らないからです。
人間の脳も特定の情報を覚えれば賢くなるわけではないのと原理は同じです。
そこで今回、スタンフォード大学の研究者たちは、chatGPTに時間経過による性能の違いがあるかを調べることにしました。
調査に当たっては
①数学的な能力
②男女問題などデリケートな質問に答える意欲
③プログラムのコード生成能力
④視覚的な推論能力
の4つの能力が2023年の「3月」と「6月」の間でどのように変化したかを調査しました。
すると驚いたことに、結果は悲惨なものになりました。






















![マモルーム お部屋まるごと予防空間 ダニ用 [2ヵ月用セット] ダニアレル物質の生成抑制・ダニを除去しやすくなる ダニよけ 加熱蒸散機 ダニ対策 (アース製薬)](https://m.media-amazon.com/images/I/413VgtLwPgL._SL500_.jpg)

![シルバーバック 【釣って遊ぼう!サメまみれ!】 知育玩具 幼稚園 小学校 入園 入学 お祝い プレゼント 準備 ([バラエティ])](https://m.media-amazon.com/images/I/41ejNUfrJZL._SL500_.jpg)