







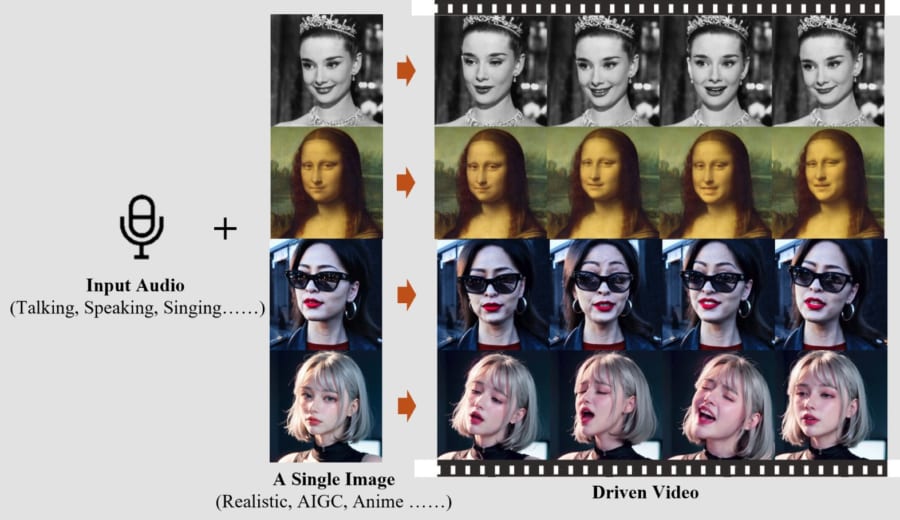
自然な表情で完璧な口パクができる!
研究者たちはこれまで、顔の静止画を処理してアニメーションバージョンを作成するAIシステムの開発を進めてきました。
アリババのAI研究チームは今回、ここに音声データを追加することで新たなステージへと突入しています。
チームが開発したEMOは、自分の選んだ好きな顔画像にどんな内容の音声データでも喋らせることのできる画期的なAIシステムです。
しかもただ単純に喋るのではなく、発話のトーンや歌の抑揚に合わせて、首をかしげたり眉根を寄せたり、目を見開いたりと自然な表情を作り出すことができます。
ざっくり言ってしまえば、EMOは顔写真に完璧な口パクをさせるシステムといえるでしょう。
しかもEMOのシステムに必要なのは、たった一枚の「顔画像」と一つの「音声データ」だけです。
従来のように、顔画像のモーションピクチャーを生成するにあたって、3Dモデルやランドマーク(目や鼻の位置など顔の特徴を抽出する上で目印となるポイント)のような中間段階は要りません。
顔画像と音声データをEMOに投げ込めば、自然なポートレート動画が生成されるように訓練されているのです。
では、それを可能にするEMOのシステムはどのような仕組みになっているのでしょうか?
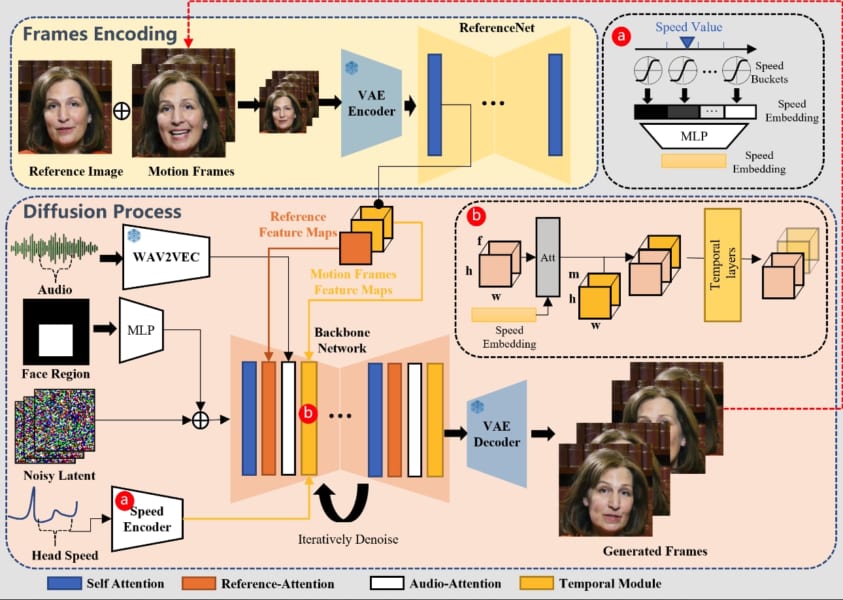
EMOの仕組み
EMOは2段階のプロセスを経てポートレート動画を生成する仕組みになっています。
1つ目は「フレーム・エンコーディング(Frames Encoding)」と呼ばれる段階です。
チームは映画やテレビ番組、スピーチや歌唱パフォーマンスの映像を延べ250時間以上も収集し、その動画データでAIをトレーニングすることで、人が会話したり歌うときにどんな表情や頭の動きをするのかを学ばせました。
これを元にフレーム・エンコーディングでは、参照する顔の静止画の特徴を分析して、あらゆる表情や頭の動きに対応できるようにします。
2つ目は「拡散プロセス(Diffusion Process)」と呼ばれる段階です。
ここでは対象とする音声データの波形を分析して、声の高さや強さ、抑揚などを理解し、それとシンクロするような口の開き、顔の表情、頭の動きの生成を開始します。
こうして訓練されたEMOのシステムは、たった一枚の顔画像と音声データを投げ込むだけで、自然なポートレート動画を生成できるようになりました。
これを使えば、写真・映画・絵画・漫画・アニメ・CGなどから切り抜いた好きな人物に、好きな音声内容を喋らせることが可能です。
完成したポートレート動画の長さは、元の音声データの長さによって決まります。
例えば、こちらはレオナルド・ダ・ヴィンチの名画『モナ・リザ』に、シェイクスピアの戯曲『お気に召すまま』の一節を喋らせたもの。
まるでモナリザが生きている人のように自然な表情と動きで喋っています。
この他にもアニメの少女やモノクロ映画の俳優を使ったでも映像が多数紹介されています。
ぜひ、こちらのリンクからご覧ください。
https://humanaigc.github.io/emote-portrait-alive/
これまでにも、好きな音声データをアバターに喋らせるAI技術は存在していましたが、ここまで人間らしい自然な表情と完璧なリップシンクを再現したのはEMOが初めてだという。
EMOは今後、映画やゲーム内での俳優・キャラクター生成のほか、バーチャルアーティストやボーカロイドの品質向上など、エンターテインメント業界での活用が期待できます。
またAIで生成した空想の彼氏や彼女と自然な会話ができるようになるかもしれません。
その一方で、EMOは政治的な悪用や芸能界のゴシップの偽造など、危険な側面も秘めていることは確かです。
EMOのようなAIシステムは使い方次第で、善にも悪にもなるでしょう。




























![ALLINLUCKY TFカード マイクロSDカード SD TF 512GB メモリーカード 高速データ転送 ミニSDカード SD変換アダプタ メモリケース付き 高安定性 [並行輸入品]](https://m.media-amazon.com/images/I/41HrWHxO7JL._SL500_.jpg)






















