



未解読8%のパンドラ開封
ヒトの全ゲノム解読が初めて達成されたのは2001年ですが、実はそのとき解明されたのはゲノムの約92%に過ぎませんでした。
残りの約8%は、塩基配列が何百万回も繰り返す「ゲノムの未開の領域」でした。
例えば、染色体の末端(テロメア)や中央部(セントロメア)には非常に長い繰り返し配列が存在します。
しかし当時のDNAシークエンサーでは、こうした大量の繰り返し配列を正確に組み立てることができず、大きな穴あきパズルのまま残されていたのです。
それから20年以上を経て、技術の飛躍的進歩がこのパズルを解き明かしました。
特にTelomere-to-Telomere(T2T)と呼ばれる新しい超長読み取りシークエンス技術により、ゲノムを端から端までギャップなく読み取ることが可能になりました。
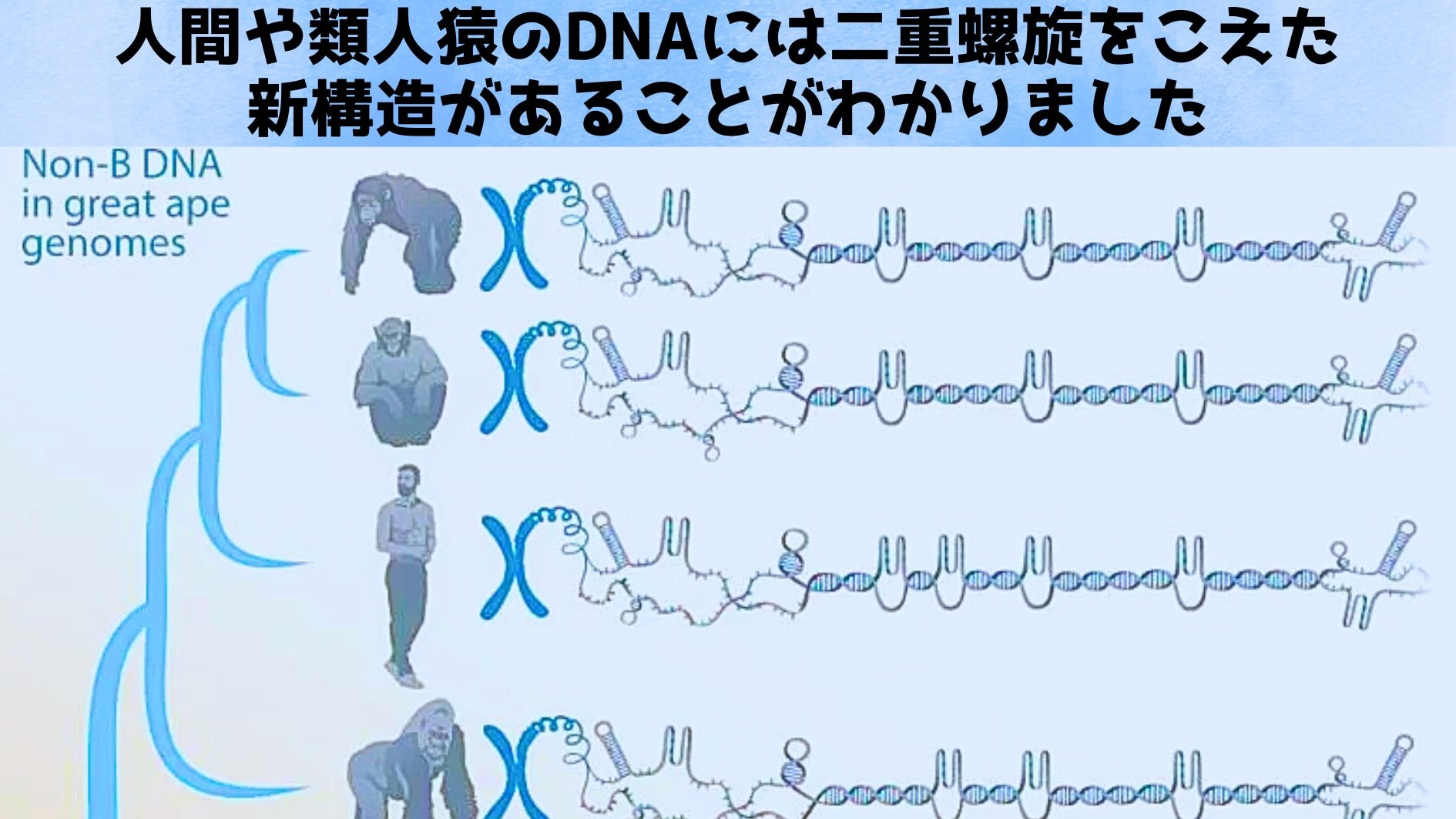
2022〜2023年にはT2Tコンソーシアムによってヒトゲノムの最後の未解明領域が次々と埋められ、さらに今年(2025年)、チンパンジー、ボノボ、ゴリラ、オランウータン(スマトラ種・ボルネオ種)および小型類人猿のシアマン(フクロテナガザル)といった大型類人猿6種+1種のゲノムが完全解読されました。
科学者たちはこの快挙により、長らく謎に包まれていた繰り返し配列の領域を初めて詳細に探るチャンスを手にしたのです。
では、なぜ繰り返し配列に注目する必要があるのでしょうか?
それは、この部分にDNAのもう一つの顔が隠されているからです。
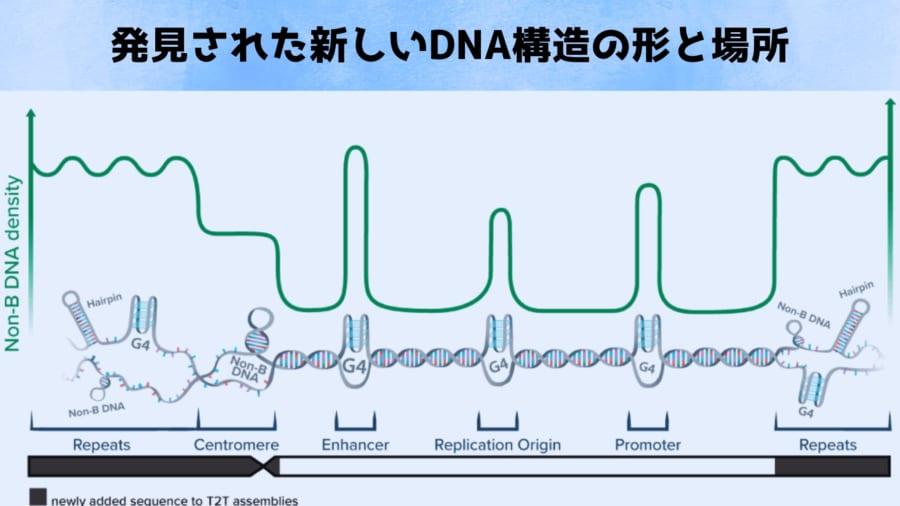
DNAは通常は右巻きの二重らせん構造(B型DNA)をとりますが、特定の配列の組み合わせによっては形を変え、「ヘアピン(髪ピン状の折れ返り構造)」や「Z-DNA(ジグザグにねじれた構造)」、「G-四重鎖構造(4本の鎖が絡んだ結び目状)」など様々な変則的な立体構造をとることがあります。
このような非典型的なDNA構造は総称して「非B型 DNA(non-B DNA)」と呼ばれます。
近年、細胞内で重要な働きをしている可能性が指摘されてきました。
例えば、DNA複製が始まるスイッチや、遺伝子のオンオフの調節、あるいは染色体を安定させるテロメア・セントロメア機能などに関与しているという報告があります。
しかし非B型を形成しやすい配列の多くは繰り返しを含むため、短い断片しか読めない旧来の技術では正確な全容把握が困難でした。
そこで今回、アメリカのペンシルベニア州立大学のカテリーナ・マコヴァ教授(生物学)ら研究チームは、T2T技術で得られた類人猿ゲノムを用いてノンB DNA構造を網羅的に探し出すことに挑みました。
完全長のゲノム配列を比較することで、非B型の進化上の役割や、生物種ごとの特徴を明らかにすることがこの研究の目的です。