AIはどうやって『怪しい雑誌』を見破った?
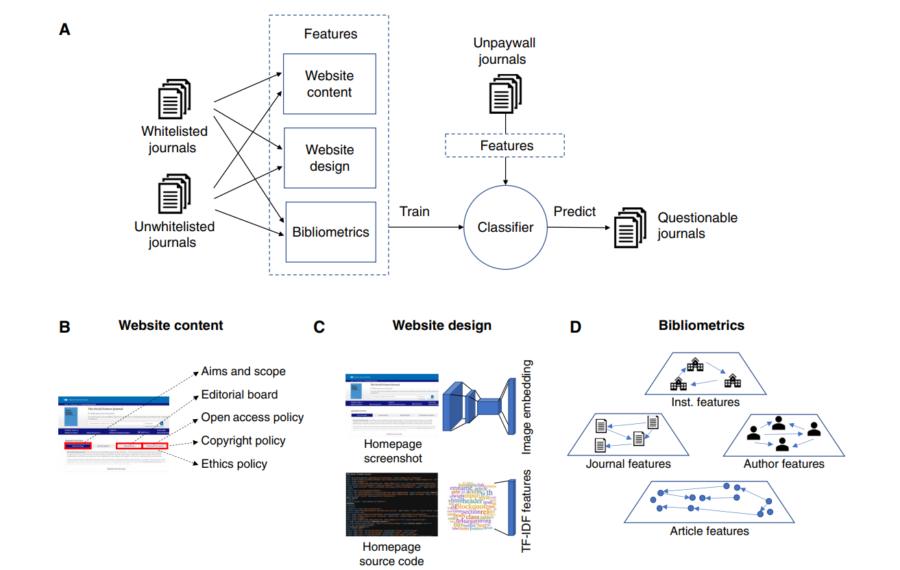
では、今回のAI(人工知能)は、どのようにして「あやしい雑誌」を見分けたのでしょうか。
まず最初に、AIが雑誌の「あやしさ」を判断するために、2つのタイプの雑誌データを用意しました。
1つは、しっかりした基準でチェックされ、品質が保証されている「信頼できる雑誌」のリストです。
もう1つは、以前は信頼されていたものの、品質の問題があったためリストから外された「疑わしい雑誌」です。
ここで重要なのは、「疑わしい雑誌」といっても、リストから除外された理由には必ずしも悪意や悪質性があるわけではないという点です。
雑誌が休刊になったり、自主的にリストから削除を依頼した場合などもありますが、それらもすべて「疑わしい雑誌」として分類されることに注意が必要です。
AIはこれら2種類の雑誌データを学習し、それぞれの雑誌がどんな特徴を持っているのかを分析しました。
具体的には、雑誌のウェブサイト上に掲載されている「編集方針」や「編集委員リスト」、「倫理規定」などの情報や、そのサイトの文章の読みやすさ(可読性:文章がわかりやすく、誤解なく読めること)を調べました。
また、サイトのデザインや構造、例えばトップページのレイアウトやウェブページを作るためのコード(HTML)のパターンなども分析対象になりました。
さらに、AIは雑誌に掲載される論文の引用パターンにも注目しました。
論文というのは、過去の研究を引用し、その上に自分の新しい研究結果を積み上げる仕組みになっています。
質の高い雑誌では、幅広くいろいろな論文を引用していますが、疑わしい雑誌では、自分たちの過去の論文ばかりを引用し、他の研究者の論文をあまり引用しない傾向があります(自己引用と言います)。
AIは、このような引用パターンも「あやしさ」の重要な手がかりとして学習しました。
こうした様々な特徴をAIに学習させ、どのような特徴が「疑わしい雑誌」に多く見られるかを教え込んでいきます。
AIが完成すると研究者たちは、実際にインターネット上で公開されている15,191の雑誌を調べてもらいました。
ここで重要となったのは2つの指標です。
1つ目の指標が「適中率(precision)」で、これはAIが「あやしい」と判断した雑誌の中で実際に本当に怪しかった割合で、高ければ高いほど優秀となります。
もう1つが「再現率(recall)」で、これはAIが本当に存在する「あやしい雑誌」全体のうち、どのくらい見逃さずに発見できたかを表し、こちらも高いほど優秀(見逃しが少ない)です。
しきい値(どのくらい厳しく判定するかの基準、あやしさへの敏感さとも言える)をちょうど中間の50%に設定した場合、AIは15,191誌のうち1,437誌を「あやしい」と判定しました。
その後、人間によってチェックを行ったところ、AIの適中率は約76%であることが判明しました。
これは「AIがあやしいと指摘した雑誌のうち、およそ4分の3にあたり1000誌以上が実際に怪しい可能性が高い」ということを示しています。
一方で再現率は約38%で、これは「実際にあやしい雑誌の4割弱をみつけられたものの、約6割を見逃している」ということを示しています。
ここで「じゃあ、もっと厳しくしたらいいのでは?」と思うかもしれませんが、そう単純ではありませんでした。
判定をゆるくして広く拾う設定にすると、無害な雑誌まで間違って疑われる確率(誤判定)が増えてしまい、チェックする人間の負担が大きくなってしまいます。
逆にしきい値を高くして本当に怪しいものだけを報告するように設定すると、報告数が減って人間の負担も減り、高精度であやしい雑誌を指定してきますが、問題のある雑誌をたくさん見逃してしまうことがわかりました。
このような、適中率と再現率の関係を「トレードオフ」(どちらかを良くするともう一方が悪くなる関係)と呼びます。
そのため研究者たちは目的にあわせて厳しさを変更する方法を提案しています。
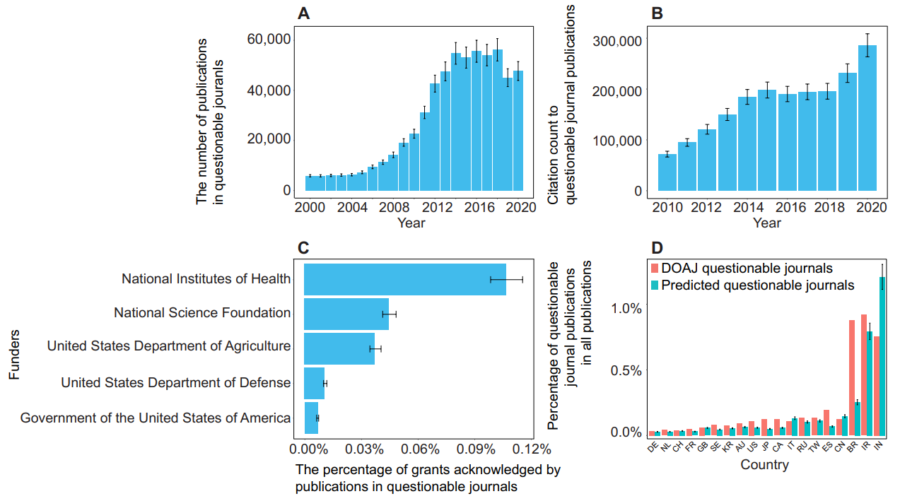
さらに、このAIによって「あやしい」と判断された雑誌を細かく調べてみると、興味深い特徴が見えてきました。
これらの雑誌では、掲載される論文の数は全体的に年々増えていましたが、2019年から2020年にかけて一時的に少し減少しました。
しかし、他の論文に引用される数(被引用数)は逆に増えており、疑わしいとされた雑誌でも論文が多く出回っていることが明らかになりました。
また、これらの雑誌に掲載された論文では、自分たちの過去の論文を頻繁に引用する「自己引用」の割合が高く、他の研究者が書いた論文の引用が少ないことも特徴でした。
さらに、その論文を書いている研究者自身も、信頼されている雑誌に掲載されている研究者に比べて平均的に業績や経験が少ない傾向がありました。
このようにして、AIは雑誌のウェブサイトの見た目だけでなく、論文の引用パターンや著者の経歴まで含めて詳しく分析することで、「疑わしい雑誌」を見分ける新しい方法を生み出したのです。



























![シルバーバック かわいい海の生きもの CUBE 2X2 キューブ ツーバイツー|海の生き物デザイン 立体パズル スピードキューブ 5cm 子ども〜大人向け 知育 ギフトに最適 ([バラエティ])](https://m.media-amazon.com/images/I/41EJOOLgGXL._SL500_.jpg)