


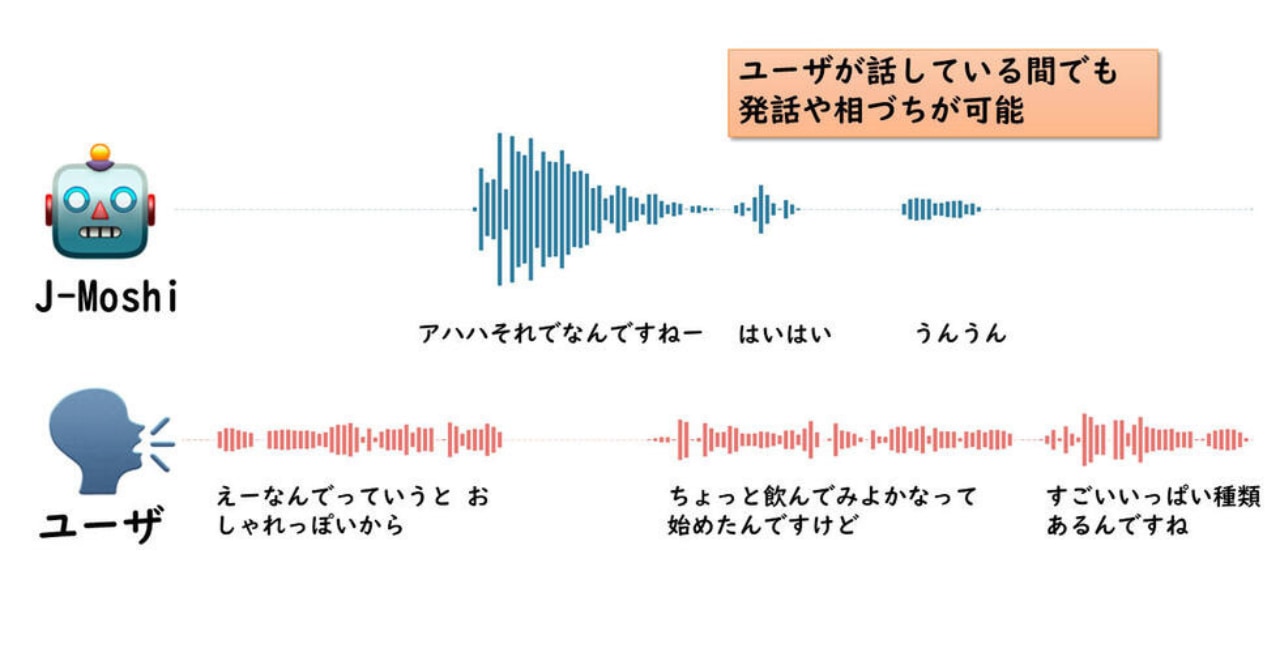




自然な音声会話ができるAIを開発!
音声アシスタントやAIチャットボットは、私たちの生活にすっかり溶け込んでいます。
スマートフォンの音声アシスタントやカスタマーサポートのAIなど、さまざまな場面で利用されています。
しかし音声AIアシスタントを使った方ならわかるように、「会話のテンポが合わないな」とか「一方的に話しかけてる感じがする」と思うことが多いでしょう。
これは従来のAIが 「ターン制」 で会話を進めるためです。
要するに、人が話し終えるまで待ち、その後にAIが応答するという方式です。ポケモンのバトルと同じですね。
一見、理にかなっているように見えますが、私たちの日常的な会話では相づちやオーバーラップ(話の重なり)が重要な役割を果たしています。
例えば、友人との会話を思い浮かべてみてください。
あなた:「昨日、新しくできたレストランに行ったんだけど…」
友人:「えっ、どこ?美味しかった?」
あなた:「そうそう、すごく美味しくて…」
と、このようにあなたが完全に話し終える前に、友達が質問を被せたり、相づちを打つことで会話はスムーズに進行します。
ところが従来の音声AIは 「相手の話を聞き終えるまで沈黙する」 ため、どうしても違和感があったり、テンポ感の遅い会話になってしまうのです。

「J-Moshi」はどうやって自然な会話を実現したのか?
名古屋大学の研究チームは、この問題を解決するために 「Full-duplex(フルデュプレックス)音声対話技術」 に着目しました。
Full-duplexとは、相手の話を聞きながら同時に話すことができる技術で、人間の会話に近いリズムを実現します。
J-Moshiは、英語版の「Moshi」という既存のモデル(7Bパラメータ)をベースに開発され、大量の日本語音声データを学習することで、日本語特有の会話の流れや相づちを適切に処理できるようになりました。
さらにAIのリアルタイム処理能力を向上させ、発話がオーバーラップしても適切に対応できるように設計されています。
例えば、
従来のAIとの会話:
あなた:「昨日、新しいレストランに行ったんだけど…」
(数秒の沈黙)
AI:「どこのレストランですか?」
J-Moshiとの会話:
あなた:「昨日、新しいレストランに行ったんだけど…」
J-Moshi:「えっ、どこの?」(すかさず、相づちを入れる)
あなた:「あの近所のスーパーの隣にできたところで。すごく美味しくて…」
J-Moshi:「へぇ!どんな料理だった?」(自然なリアクション)
このようにJ-Moshiは 会話のテンポを崩さず、より人間らしい対話を実現します。
では、研究で行われた実際の会話を聴いてみましょう。
こちらのページでご視聴できます。

どうでしたか?あまりに滑らかで、どちらがAIでどちらが人間かもはや区別がつきませんね。
これまでの音声AIとの会話は「命令を伝えるツール」としての役割が強く、雑談にはあまり向いていませんでした。
しかしJ-Moshiの登場によって、AIと「自然におしゃべりする」未来が現実になりつつあります。
この技術が進化すれば、接客やカウンセリング、さらには一人暮らしの高齢者の話し相手など、幅広い分野での活用が期待されます。
「AIとの会話が楽しい」と感じる日が来るのも、そう遠くないかもしれません。





















![マモルーム お部屋まるごと予防空間 ダニ用 [2ヵ月用セット] ダニアレル物質の生成抑制・ダニを除去しやすくなる ダニよけ 加熱蒸散機 ダニ対策 (アース製薬)](https://m.media-amazon.com/images/I/413VgtLwPgL._SL500_.jpg)































こんにちは