


次世代AIモデルの開発における課題
生成AIモデルは、既存のサンプルから学習して、新たな合成データを生み出すことができます。
例えば、様々な人間の顔写真でトレーニングした生成AIモデルは、実在しない人間の顔の画像を新たに作成することができます。
最近ではAIの性能が高まっているため、AI画像と本物の写真を見分けることは容易ではありません。
また、ネット上には様々なAI画像があふれるようになりました。

しかしライス大学の研究によると、この状況は次世代のAIモデルを開発する際、大きな問題を引き起こす恐れがあります。
新しいAIモデルを開発し、トレーニングするためには膨大な量のオリジナルデータが必要であるため、開発者たちはその供給に難儀することになります。
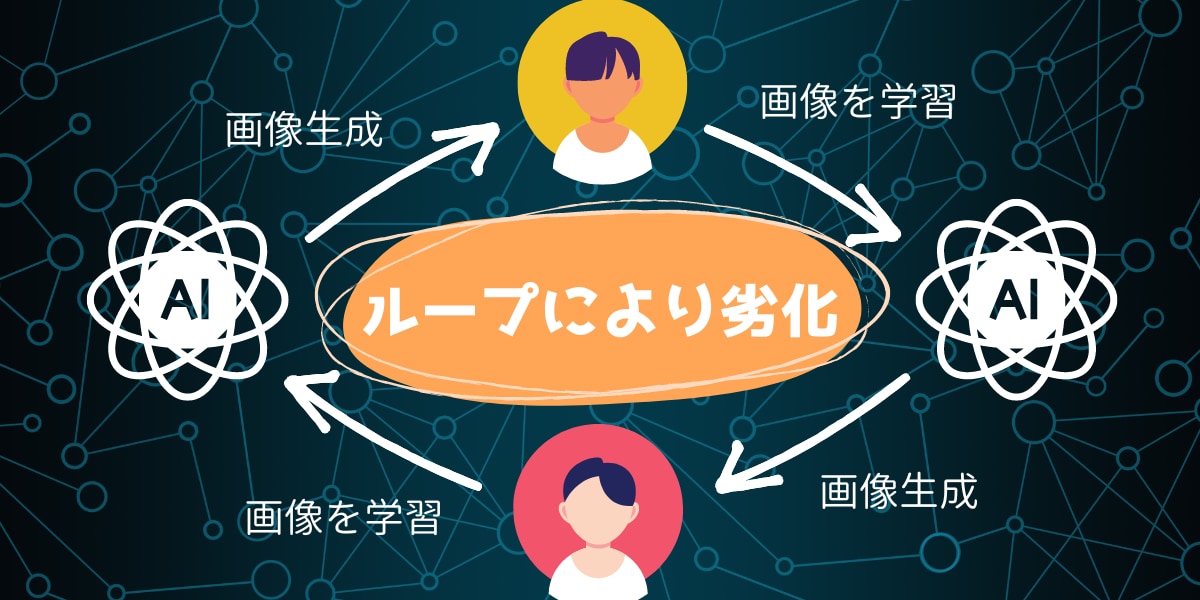
そのため、次世代AIモデルのトレーニングでは意図的に、AI生成データが使用されたり、ネット上の情報で学習することで知らない内にAI生成データで学習してしまう可能性があるのです。
つまり、「AIにAIが生成したデータを与える」現象が生じるわけです。
AIの作った文章にしろ、AI生成画像にしろ、人間の目にもわかりやすい問題を抱えている場合がよくありますが、こうした欠陥を含んだデータで新しいAIモデルが学習してしまうと、生成されるデータ(画像、テキスト、その他のデータ含む)の品質と多様性かどんどん低下していく恐れがあります。
そこで今回の研究チームは、AIにAI生成データを与えて学習させた結果、どのような現象が生じるのか実験を行いました。


























![【カンタン!たのしい!水の生きもの砂絵セット】 知育玩具のシルバーバック 幼稚園 小学校 入園 入学 お祝い プレゼント 準備 ([バラエティ])](https://m.media-amazon.com/images/I/515gZ4F-QYL._SL500_.jpg)
![ラボン(Lavons) 柔軟剤 特大 シャイニームーン[フローラルグリーン] 詰め替え 3倍サイズ 1440ml](https://m.media-amazon.com/images/I/41ze0Blp9fL._SL500_.jpg)



























