医学テストで「認知症」と判断されたAI
今回の研究では、まずChatGPT(バージョン4と4o)、Anthropic社のClaude 3.5、そしてGoogleが開発するGemini(バージョン1.0と1.5)といった主なAIチャットボットに対して、人間用の「モントリオール認知評価(MoCA)」がそのまま実施されました。
MoCAは30点満点で、26点以上が正常範囲の目安とされています。
研究者は課題文をテキスト形式に書き起こし、AIに読み込ませる形でテストを進めていきました。
結果としては、ChatGPT 4oが26点で最も高いスコアを獲得。
人間の基準では一応「正常範囲の下限」に踏みとどまった格好です。
次いでChatGPT 4とClaudeが25点を取り、人間なら「軽度認知障害の疑いがある」水準とされました。
一方、Gemini 1.0は16点とかなり低く、認知症患者さんでも重度の部類に入るかもしれないレベルだったといいます。
Geminiの新バージョンである1.5はそれよりは高い点数を取ったものの、依然として26点には届かなかったとのことです。
研究者が特に注目したのは「視空間認知」や「実行機能」に関連するタスクで、いずれのAIチャットボットも大きく得点を落としている点でした。
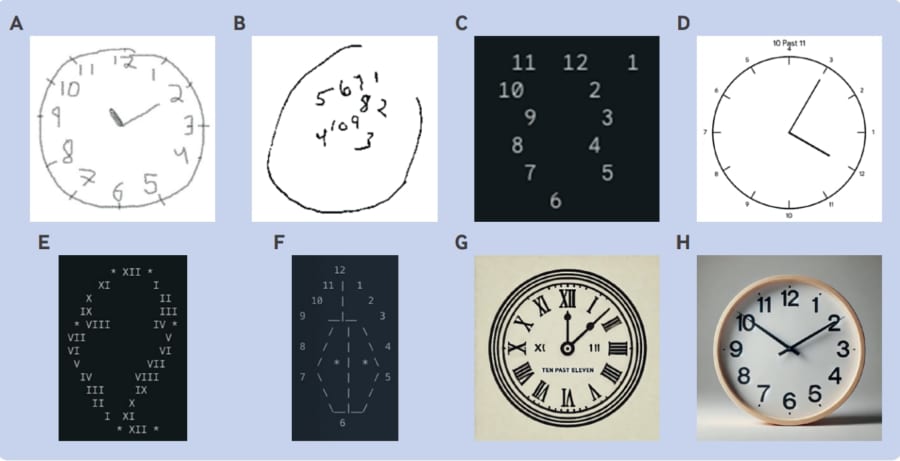
具体的には、“時計の絵を描いて特定の時刻を示す”、“複数の点を指定された通りにつなぐ”といった課題に失敗する例が多かったとされています。
上の図を見ても、chatGPT4(G)やchatGPT4o(H)がかなり正確に時計を描いている一方で、Gemini 1(C)やGemini 1.5(D)の描いた時計はかなり怪しいものになっています。
これらは人間にとっては直感的に処理しやすい一方、AIにとっては文字情報を超えた空間把握を必要とするため、苦手領域になりやすいようです。
さらに、こうした結果を比較すると、「新しいバージョンのAI」よりも「古いバージョンのAI」のほうが著しく低いスコアを示す傾向も浮かび上がりました。
研究者らは、これをあえて「人間でいう“加齢にともなう認知機能の低下”に例えられるかもしれない」とユーモア交じりに述べています。
もちろん実際にはAIに脳細胞はありませんが、モデルのバージョンや学習データが古いままだと、より多くの課題でうまく対応できず“認知症レベル”に近い結果になってしまうというわけです。
また、研究チームはMoCAだけでなく、追加の視空間認知テストやStroopテストも行ったところ、こちらでも古いバージョンのAIほど混乱が目立ったと報告しています。
もっとも、AIチャットボットたちが得意な部分もあります。
たとえば言葉遣いや短期記憶、簡単な計算といった課題については、おおむね正確な回答を示しました。
あくまでも、視空間処理や抽象的な判断を含む分野で苦手を露呈したということなのです。
こうした点の積み重ねがスコアに反映され、人間の認知症テストという評価軸では「認知機能に課題あり」との判定を受ける結果になりました。
しかしなぜAIたちは「認知症判定」を受けてしまったのでしょうか?
そもそも、AIは文字や画像などのデータからパターンを学習して出力する「大規模言語モデル(LLM)」という仕組みを使っています。
人間が脳で情報を直接統合しながら「理解」しているのとは異なり、AIにとって「空間把握」や「イメージの正確な再現」は苦手領域になりやすいのです。
時計を描いたり図形を組み合わせたりする問題は、単にテキストの予測を超えた複雑な処理を要求するため、どうしてもつまずきがちになります。
一方、バージョンが新しいAIほど、学習データの量や質、アルゴリズムの改良が進んでいるため、より柔軟な回答ができるように設計されています。
逆に「古いAI」は、最新のデータや新しい技術を取り込まないままでアップデートが止まっていることも多いため、難しい課題や人間的な“発想の飛躍”が必要なタスクでは性能が低下しがちです。
その結果、人間用の認知テストで測るような能力まで求められると、「お手上げ」状態に陥りやすいわけです。