



マインクラフト実験で「自分で極める」と「人を真似る」の最良バランスが判明
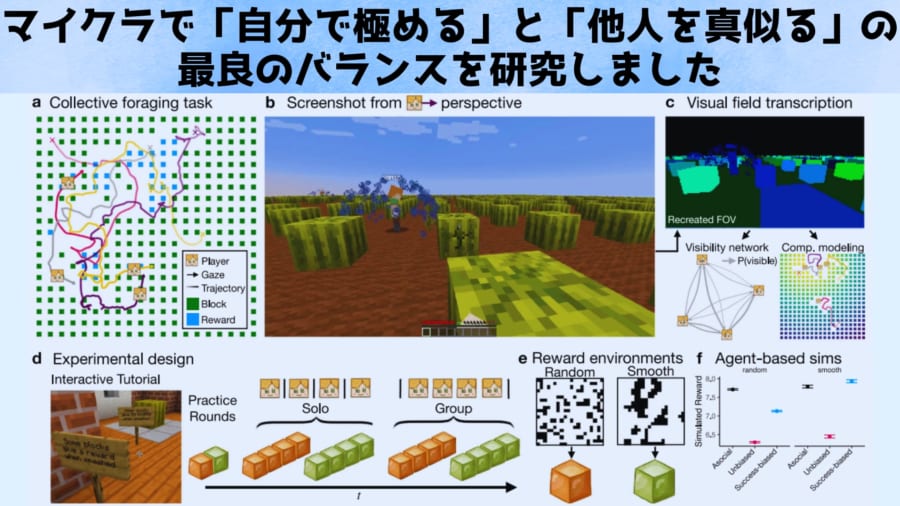
参加者はパソコン上のマインクラフト世界に没入し、資源探しに挑みました。
本研究では、プレイヤー各自がゲーム内で何を見ているか(視野データ)を自動的に記録する革新的な手法も導入されました。
画面に映るブロックや出来事、他のプレイヤーの姿が20分の1秒ごとに保存され、各参加者がどこに注意を向けていたのかが詳細に追跡されたのです。
さらに、蓄積された視野・行動データをもとに、参加者が次にどのブロックを掘るかを予測する計算モデルも構築されました。
実験では各参加者がマインクラフト内のアバターを操作し、地中に隠れた資源ブロック(スイカやカボチャ)を探しました。
ブロックを壊して資源を発見すると、その地点に青いスプラッシュのエフェクトが現れます。
これは他のプレイヤーからも見えるため、周囲にさらなる資源がある場所を示す「手がかり」として利用できます。
各ラウンドの始めに参加者には、自分ひとりで探索するか、リアルタイムで互いにやりとり可能な4人グループの一員として探索するかが割り当てられます。
また環境には2種類あり、資源が塊状に集中している「パッチ型」では一箇所で見つかれば近くに他の資源が眠っている可能性が高いのに対し、資源がまばらに散らばる「ランダム型」では場所に規則性がなく手がかりの価値はありません。
参加者たちは協力ではなく各自ができるだけ多くの資源を集めることを目指すため、状況に応じて単独行動と他者からの学習を上手に使い分けて報酬を探す必要があります。
分析を主導したチャーリー・ウー氏(チュービンゲン大学)は、「簡単に言えば、個人学習と社会学習の戦略をすべて一つの計算フレームワークに統合することで、参加者が次にどのブロックを選ぶかを予測できるようになりました。
この新しいアプローチにより、現代のAIを支える学習アルゴリズムと、他者の成功行動から柔軟に学ぶ社会的学習メカニズムとを結びつけることが可能になります」と述べています。
こうしたデータ分析により、戦略を状況に合わせて柔軟に切り替える適応力が高い人ほど多くの資源を獲得し、成績が良いことが明らかになりました。
逆に、最初から最後まで個人での探索だけ、あるいは他者の手がかり頼みだけ、といったように戦略を固定してしまった人は、あまり成果を伸ばすことができませんでした。
また、プレイヤーがいつ社会的な手がかりに頼るか、いつ自分一人で探索するかという判断は、その時点での自分自身の成果に大きく左右されていることも分かりました。
自力で順調に資源を見つけられているときには探索を続け、行き詰まると他のプレイヤーのヒント(青いスプラッシュ)を追いかける――各参加者は自分のパフォーマンスを“共通通貨”、すなわち共通の指標として両学習戦略を切り替えていたのです。
研究によって発見された最高効率を出す方法
研究チームが示した答えはとてもシンプルです。――まずは自分で試してうまくいっているうちは、とことん「ひとり探索」を続ける。ところが手詰まりになって成果が途切れた瞬間、視線を周囲に向け、直近で成果を上げた人だけを素早く見つけて真似する。そしてまた自分の手で連勝できるようになったら、迷わず単独行動へ戻る――この“息継ぎ”のようなリズムこそが最適解でした。とくに資源が塊で眠る環境では仲間の発見情報が金脈の手がかりになるため模倣を厚くし、資源がバラけている環境では逆に自力探索を優先する切り替えが功を奏しました。要するに「調子がいいときは自分流、伸び悩んだら成功者の背中を追う」という単純なルールを、状況に合わせて繰り返し行うことで、人は複雑な世界でも最短で学べるというわけです。





























![シルバーバック 【釣って遊ぼう!サメまみれ!】 知育玩具 幼稚園 小学校 入園 入学 お祝い プレゼント 準備 ([バラエティ])](https://m.media-amazon.com/images/I/41ejNUfrJZL._SL500_.jpg)




























