MuZeroはルールを教えられなくても、従来のAIを超える能力を獲得した
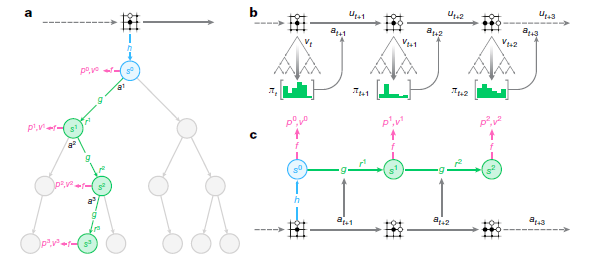
MuZeroはルールを把握するために、環境から次の3要素をモデル化します。
①値:現在の位置はどれくらい良いか?
②方針:どのアクションを実行するのが最適か?
③報酬:最後の行動はどれくらい良かったか?
つまりMuZeroは、成功した手法から学び、失敗した手法を避け、関連性と成功率が最も高い操作を優先していくのです。
従来のAIは「ルール」と「先読み検索」という原則で成り立っています。そのためルールに基づいて対戦相手が指し得る膨大な手を予測し、すべて評価しなければいけませんでした。
しかし、MuZeroは「経験から学ぶ手法」であり、そこから最善の手を生み出します。そのためルールが与えられていなくても戦えますし、試行回数が増えるにつれて能力も向上していきます。
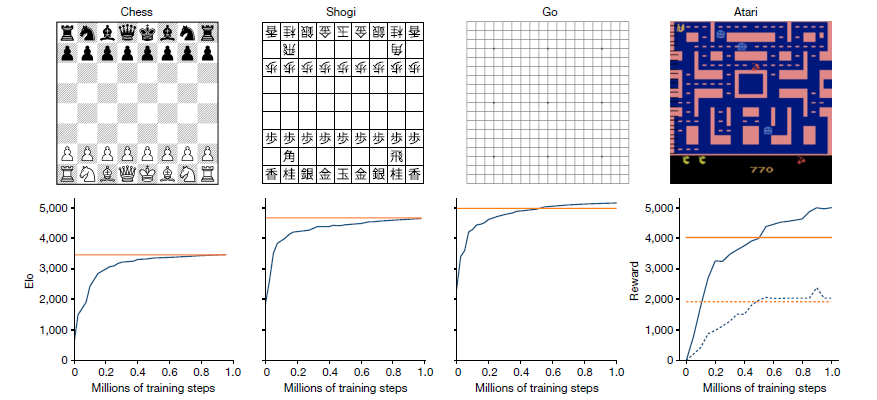
実際、MuZeroはシンプルなルールの囲碁、チェス、将棋において従来のAIと同等の能力を身に着け、場合によっては打ち負かすこともできたとのこと。
さらに、画像情報が多いため従来のAIではモデル化が難しいとされていたビデオゲーム「Atari」の57作品(パックマンのようなクラッシックゲームなど)においても、ルールを一切教わらずに、一般的な人間に勝てるようになったというのです。
さて、今回の報告によって、AIがゲームの分野で「ルールを発見し、一般的な人間や従来のAIを超える」という大きな課題をクリアしたと分かります。
このアルゴリズムを応用すれば、「ルールが知られていない」ロボット工学、産業システム、または現実世界の環境における新たな問題を解決するのに役立つかもしれません。